ASPiRe: Adaptive Skill Priors for Reinforcement Learning

We introduce ASPiRe (Adaptive Skill Prior for RL), a new approach that leverages prior experience to accelerate reinforcement learning. Unlike existing methods that learn a single skill prior from a large and diverse dataset, our framework learns a library of different distinction skill priors (i.e., behavior priors) from a collection of specialized datasets, and learns how to combine them to solve a new task. This formulation allows the algorithm to acquire a set of specialized skill priors that are more reusable for downstream tasks; however, it also brings up additional challenges of how to effectively combine these unstructured sets of skill priors to form a new prior for new tasks. Specifically, it requires the agent not only to identify which skill prior(s) to use but also how to combine them (either sequentially or concurrently) to form a new prior. To achieve this goal, ASPiRe includes Adaptive Weight Module (AWM) that learns to infer an adaptive weight assignment between different skill priors and uses them to guide policy learning for downstream tasks via weighted Kullback-Leibler divergences. Our experiments demonstrate that ASPiRe can significantly accelerate the learning of new downstream tasks in the presence of multiple priors and show improvement on competitive baselines.
Paper
Neural Information Processing Systems / NeurIPS 2022

Team



Columbia University in the City of New York
BibTeX
@inproceedings{
xu2022aspire,
title={{ASP}iRe: Adaptive Skill Priors for Reinforcement Learning},
author={Mengda Xu and Manuela Veloso and Shuran Song},
booktitle={Thirty-Sixth Conference on Neural Information Processing Systems},
year={2022},
url={https://openreview.net/forum?id=sr0289wAUa}
}
}ASPiRe Overview
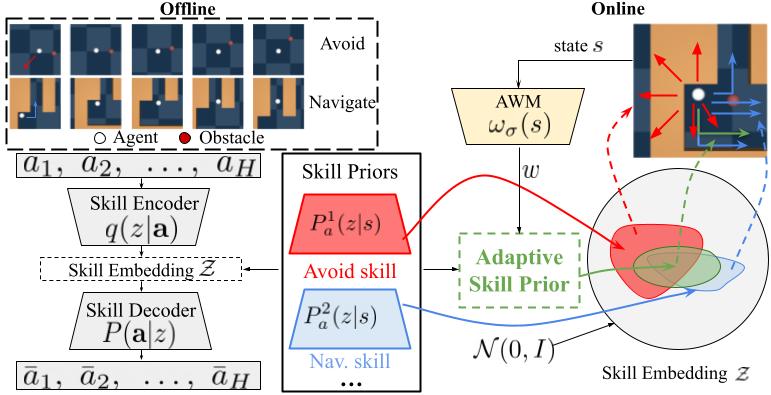
Our approach consists of two learning stages: offline and online (See Fig above). In the offline stage, the system learns multiple primitive skill priors from a set of labeled datasets. Each dataset contains expert demonstrations of one specific primitive task. In the online stage (for downstream tasks), the algorithm creates an adaptive skill prior by assigning weight over primitive skill priors. Our method includes an Adaptive Weight Module (AWM) that infers an adaptive weight assignment over learned primitive skill priors and uses these inferred weights to guide policy learning through weighted Kullback-Leibler (KL) divergence. The weight applied to the KL divergence between the learned policy and a given primitive skill prior determines its impact on the learned policy. This implicitly composes multiple primitive skill priors into a composite skill prior and guides the policy learning. Our formulation allows the algorithm to combine the primitive skill priors both sequentially and concurrently as well as adaptively adjust them during the online learning phase.
Learning optimal weights
To demonstrate ASPiRe's ability to learn optimal weights, we visualize the weights generated by the weighting function for the primitive skills priors at different states for point maze, ant maze and robotic manipulation environments.

ASPiRe is able to compose the navigation prior and avoid prior concurrently (grey phases) when the obstacle is observed and only activate navigation prior when it is not (white phases).
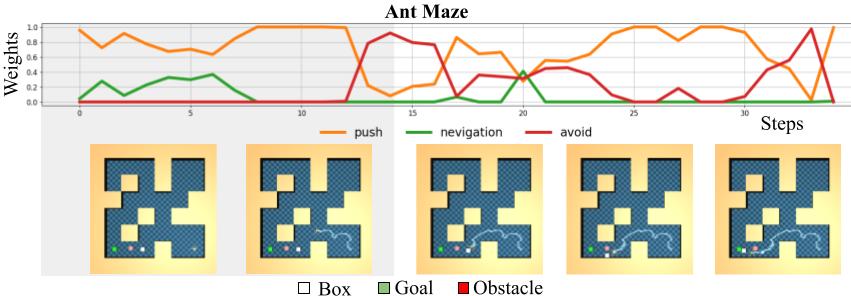
In the grey phase, ASPiRe is able to compose the navigation prior and push prior concurrently to traverse the maze and reach the box. In the white phase, the model composes the push and avoid prior to push the box to the goal while avoiding the obstacle along the way.
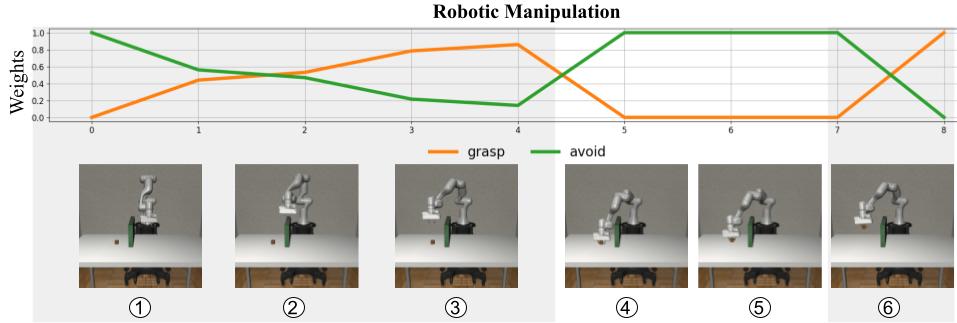
In the first grey phase (sub-figure 1, 2, 3), ASPiRe is able to compose the grasp prior and avoid prior concurrently to lift the robot arm to avoid the barrier while approach to the box. In the white phase, notice that the robot arm is initially very close to the barrier (sub-figure 4). To avoid any potential collision between the robot arm and the barrier, ASPiRe activates the avoid prior to move the robot arm away from the barrier (sub-figure5). In the end, ASPiRe activates the grasp prior to grasp the box.
Contact
If you have any questions, please feel free to contact Mengda Xu.